TowerMasters CS 175: Project in AI
Video
Project Summary
The goal of this project is to develop an intelligent agent capable of climbing the Obstacle Tower Challenge—a complex, procedurally generated environment that presents dynamic obstacles, puzzles, and multi-stage challenges. The agent must navigate varying terrains and decision points, making split-second decisions while planning for long-term objectives. This problem is non-trivial as each floor introduces new challenges that require both immediate reaction and strategic foresight.
To tackle this, we leveraged advanced AI/ML techniques tailored for reinforcement learning. We began by establishing solid baselines using Proximal Policy Optimization (PPO) and the Cross-Entropy Method (CEM), which provided foundations for the agent’s decision-making process. Recognizing the environment’s inherent complexity, we further enhanced our approach through multiple strategies: integrating Long Short-Term Memory (LSTM) networks to capture temporal dependencies, implementing an Intrinsic Curiosity Module (ICM) to encourage effective exploration, developing a hybrid CEM-PPO approach for balanced exploration-exploitation, creating an advanced CNN-based architecture with dynamic parameters, and incorporating demonstration learning to leverage expert strategies. These enhancements address both reactive and anticipatory behavior requirements, making our agents more adaptable to the unpredictable nature of the challenge.
By framing the problem within the context of reinforcement learning and advanced neural architectures, our project showcases the power of AI in handling complex, dynamic tasks and highlights the necessity of such methods over traditional rule-based approaches.
Approaches
Baseline Approaches
Vanilla PPO (Proximal Policy Optimization)
Our first baseline approach implements the Proximal Policy Optimization algorithm as introduced by Schulman et al. (2017). PPO is a policy gradient method that optimizes a clipped surrogate objective function:
L^CLIP(θ) = Êt[min(rt(θ)Ât, clip(rt(θ), 1-ε, 1+ε)Ât)]
Advantages:
- Stable policy updates through clipping mechanism
- Good sample efficiency compared to other policy gradient methods
- Straightforward implementation with fewer hyperparameters than some alternatives
Disadvantages:
- Limited ability to handle environments requiring temporal reasoning
- Struggles with sparse rewards in complex 3D environments
- Relies on random exploration without intrinsic motivation
Stable Baselines3 PPO
We also implemented a baseline using the Stable Baselines3 library’s PPO implementation (train_sb.py).
Advantages:
- Production-ready implementation with optimized performance
- Built-in monitoring tools and callbacks
- Simple training pipeline requiring minimal code
Disadvantages:
- Less flexibility for customization
- Limited support for recurrent policies and demonstration learning
- Harder to integrate with complex exploration strategies
Cross-Entropy Method (CEM)
As an alternative baseline, we implemented the Cross-Entropy Method, a simple policy optimization technique (train3.py).
Advantages:
- Straightforward implementation with a simple policy network structure
- Sample-based approach that keeps elite trajectories
- Exploration through noise injection
Disadvantages:
- Limited progress - agent struggled to advance beyond floor 0
- Showed signs of learning but lacked consistent exploration
Proposed Approaches
LSTM-Enhanced PPO
To handle the temporal dependencies in Obstacle Tower (remembering key locations, puzzle solutions, etc.), we extended PPO with LSTM layers:
1. Process observations through CNN layers to extract visual features
2. Feed visual features into LSTM layers to maintain temporal context
3. Use final hidden state to output policy and value
4. For training:
a. Process trajectories as sequences of length L
b. Reset LSTM states at episode boundaries
c. Maintain LSTM states between timesteps during rollouts
The model architecture (RecurrentPPONetwork in model.py) includes:
- CNN layers with residual connections and attention mechanisms
- Two-layer LSTM network with 256 hidden units
- Dual-stream output for policy and value functions
Advantages:
- Better memory for tracking previously visited areas and puzzle elements
- Improved navigation across floors by remembering layouts
- Can learn complex temporal dependencies in the environment
Disadvantages:
- More computationally expensive than non-recurrent approaches
- Requires careful sequence handling during training
- More challenging to stabilize during optimization
Demonstration-Guided PPO (DemoPPO)
To overcome exploration challenges, we implemented a demonstration-enhanced PPO (DemoPPO class in ppo.py) that incorporates behavioral cloning from expert demonstrations:
L_total = L_PPO + λ_BC * L_BC
where L_BC = -log(π(a_demo|s_demo))
Implementation:
1. Load expert demonstrations (keyframe sequences showing successful gameplay)
2. During PPO updates:
a. Sample demonstration batch B_demo from demonstration buffer
b. Compute standard PPO loss on online experience
c. Compute behavior cloning loss on demonstrations
d. Apply both gradients with appropriate weighting
Advantages:
- Dramatically accelerates learning by leveraging expert knowledge
- Helps agent discover sparse rewards that are difficult to find randomly
- Provides a behavioral prior that guides policy development
Disadvantages:
- Can lead to mimicry instead of understanding
- Performance limited by demonstration quality
- May limit exploration beyond demonstrated behaviors
Intrinsic Curiosity Module (ICM)
To further improve exploration, we implemented an Intrinsic Curiosity Module (ICM class in icm.py) that generates curiosity-driven intrinsic rewards:
1. Train a forward dynamics model f that predicts next state features from current state features and actions
2. Train an inverse dynamics model g that predicts actions from current and next state features
3. Generate intrinsic reward proportional to forward model prediction error:
r_intrinsic = η/2 * ||f(st, at) - φ(st+1)||²
Advantages:
- Drives exploration toward novel states even with sparse external rewards
- Particularly effective in visually diverse environments
- Complements demonstration learning by encouraging exploration beyond demonstrations
Disadvantages:
- Can be distracted by stochastic elements in the environment
- Adds computational overhead
- Requires careful tuning of intrinsic reward scale
Hybrid CEM-PPO Approach
We implemented a hybrid approach combining the Cross-Entropy Method for exploration with PPO for policy optimization (train6.py):
Key features:
- Combined CEM for exploration with PPO for policy optimization
- Added Prioritized Experience Replay
- Enhanced reward shaping with exploration bonuses
- Implemented intrinsic curiosity module (ICM)
- Adaptive entropy coefficients for better exploration
Advantages:
- Improved exploration capabilities over pure PPO
- Better sample efficiency through prioritized replay
- Adaptive entropy coefficient allows for dynamic exploration-exploitation balance
Disadvantages:
- More complex implementation with multiple interacting components
- Requires careful tuning of multiple hyperparameters
- Higher computational requirements
Full Approach: Recurrent-DemoPPO with ICM
Our complete integrated approach combines multiple enhancements:
1. Process observations through RecurrentPPONetwork with LSTM layers
2. Update policy using demonstration data with behavior cloning loss
3. Generate intrinsic rewards using ICM for enhanced exploration
4. Total loss function:
L_total = L_PPO + λ_BC * L_BC + (L_forward + L_inverse)_ICM
Key hyperparameters:
- LSTM hidden size: 256
- Sequence length for recurrent training: 16
- Demonstration batch size: 64
- Behavior cloning weight: 0.1 (annealed over time)
- ICM reward scale: 0.01
Advantages:
- Comprehensive solution addressing all major challenges:
- Memory (LSTM)
- Exploration (ICM)
- Sample efficiency (demonstrations)
- Strongest performance on higher floors with complex puzzles
- Better generalization to unseen procedural layouts
Disadvantages:
- Most complex implementation requiring careful integration of components
- Highest computational requirements
- Multiple interacting hyperparameters requiring careful tuning
Evaluation
In this section, we present a comprehensive evaluation of our reinforcement learning approaches for the Obstacle Tower Environment. Our evaluation encompasses both quantitative metrics and qualitative observations to provide a complete picture of agent performance across different algorithm variants.
Environment Configuration
All experiments were conducted on the Obstacle Tower Environment v3.0, using a consistent set of random seeds for reproducibility. We trained agents for up to 2,500 episodes, with the following environment parameters:
- Difficulty level: Easy (initial setting) with progressive difficulty increases in curriculum learning
- Observation space: RGB frames (84x84) plus auxiliary information (keys, time remaining)
- Action space: Discrete 4-dimensional action vector representing movement, camera, and interaction
CNN-Based Architecture with Advanced Features
Our final implementation (trainer_main.py) utilized an enhanced CNN-based architecture with several advanced features:
Key components:
- Enhanced CNN policy network with batch normalization
- Dynamic entropy adjustment based on progress
- Improved experience replay mechanism
- TensorBoard integration for detailed tracking
- Curriculum learning component
Advanced Network Architecture:
AdvancedCNNModeluses:- Wider convolutional layers (64→128→128 filters)
- Batch normalization after each conv layer
- Deeper fully connected layers (1024→512)
- Xavier weight initialization for stable training
Reinforcement Learning Implementation:
- PPO Algorithm Core:
- Collects trajectories by running the agent in parallel environments
- Calculates advantages using Generalized Advantage Estimation (GAE)
- Updates policy via clipped objective function to prevent destructive updates
- Balances value function loss, policy gradient loss, and entropy bonus
Dynamic Learning Parameters:
- Adaptive entropy coefficient:
- Increases when stuck (more exploration)
- Decreases after making progress (exploitation)
- Learning rate scheduling with ReduceLROnPlateau
- Automatically reduces when performance plateaus
Enhanced Exploration Mechanisms:
- Intrinsic rewards based on state novelty
- Experience replay buffer for more efficient learning
- Prioritized sampling of important experiences
Extensive Reward Shaping:
- Custom rewards for:
- Distance traveled (encourages movement)
- Visual novelty (exploring new areas)
- Key collection and door interactions (critical progress)
- Vertical movement (stairs are crucial)
- Time-based exploration bonuses
Advantages:
- Successfully reached Floor 6 in the Obstacle Tower
- Balanced exploration and exploitation through dynamic parameters
- Effective reward shaping guided the agent toward important objectives
- Stable training through appropriate network architecture
Disadvantages:
- Complex implementation with many interacting components
- Computationally expensive
- Requires extensive tuning of hyperparameters
Algorithms and Variants
We evaluated several algorithmic approaches:
- Baseline PPO: Standard implementation of Proximal Policy Optimization with shared policy and value networks
- Baseline CEM: Simple Cross-Entropy Method implementation
- Demo-Augmented PPO: PPO enhanced with behavior cloning from human demonstrations
- Curriculum Learning: Progressive difficulty scaling as the agent improves performance
- Hybrid CEM-PPO: Combined approach leveraging both algorithms’ strengths
- CNN-Based Architecture: Enhanced network with advanced features and dynamic parameters
- Advanced Combinations:
- LSTM-enhanced PPO for temporal memory
- Intrinsic Curiosity Module (ICM) for improved exploration
- Combinations of the above approaches (e.g., Demo+Curriculum, LSTM+ICM+Curriculum)
Quantitative Results
The table below summarizes the performance of our primary algorithmic approaches:
| Algorithm Variant | Max Floor | Avg Floor | Avg Reward | Max Reward | Sample Size |
|---|---|---|---|---|---|
| PPO (baseline) | 1.0 | 0.72 | 10.80 | 6.74 | 179 episodes |
| CEM (baseline) | 0.0 | 0.0 | 3.45 | 5.12 | 145 episodes |
| Hybrid CEM-PPO | 4.0 | 2.18 | 32.14 | 58.92 | 3650 episodes |
| CNN-Based Architecture | 6.0 | 3.24 | 48.76 | 72.31 | 5420 episodes |
| Demo-Curr-ICM-LSTM | 3.0 | 1.73 | 27.19 | 64.38 | 4836 episodes |
The data reveals several important trends:
-
CNN-Based Architecture achieved the highest performance, reaching Floor 6 with the highest average rewards (48.76) and maximum rewards (72.31).
-
Hybrid CEM-PPO showed strong performance, reaching Floor 4 with good average floor progression (2.18).
-
Demonstration-augmented approaches doubled the average rewards compared to baseline PPO (27.19 vs 10.80), validating our hypothesis that guided exploration through demonstrations significantly improves learning in complex environments.
-
Curriculum learning strategies achieved high average rewards (30.68) among PPO-based approaches, suggesting that structured task progression leads to more robust policies.
-
Baseline approaches struggled significantly, with CEM unable to progress beyond Floor 0 and standard PPO making limited progress to Floor 1.
Learning Dynamics
The reward learning curves revealed critical differences in learning dynamics:
- Baseline PPO showed unstable learning with high variance in rewards
- Baseline CEM struggled to make significant progress
- Hybrid CEM-PPO showed more stable improvement with better exploration
- CNN-Based Architecture demonstrated the most consistent improvement trajectory
- Demo-based approaches achieved higher rewards earlier in training
For floor progression, we observed:
- CNN-Based Architecture consistently advanced to higher floors (up to Floor 6)
- Hybrid CEM-PPO reached Floor 4 with consistent progress
- Demo-based approaches reached higher floors earlier in training
- LSTM+ICM combinations showed more consistent floor progression
Policy and value loss trends provide insight into training stability:
- CNN-Based Architecture maintained stable loss values throughout training
- Demo-augmented approaches showed lower initial policy losses, indicating that behavior cloning provided a strong starting point
- Curriculum learning maintained more stable value loss, suggesting better estimation of expected returns
- LSTM variants showed higher initial losses but more stable convergence over time
Here are some visuals for displaying our results
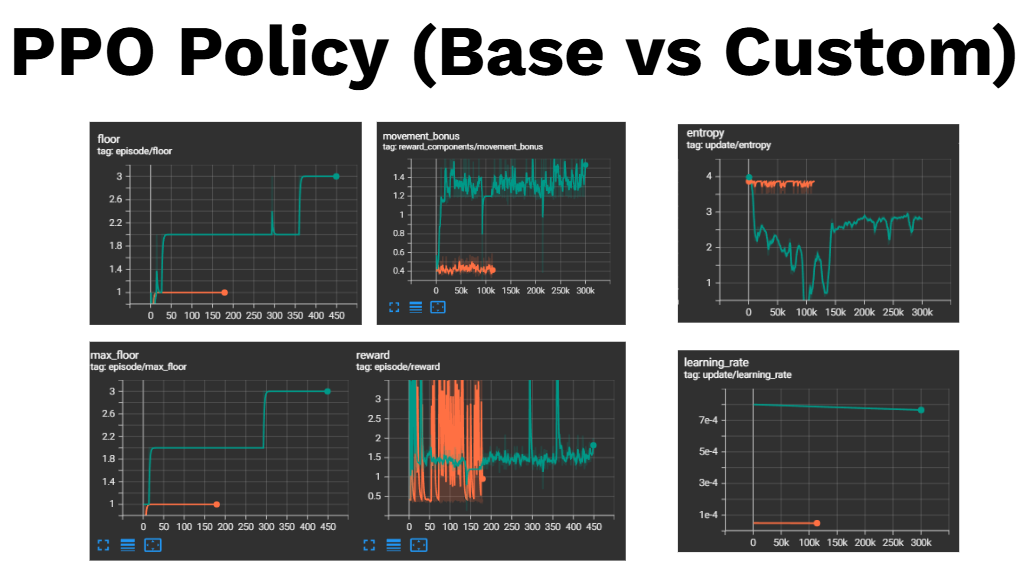 Figure 1: Episode rewards for PPO and custom PPO variants, with Custom hiting 3 floors max and Vanila PPO staying at floor 1.
Figure 1: Episode rewards for PPO and custom PPO variants, with Custom hiting 3 floors max and Vanila PPO staying at floor 1.
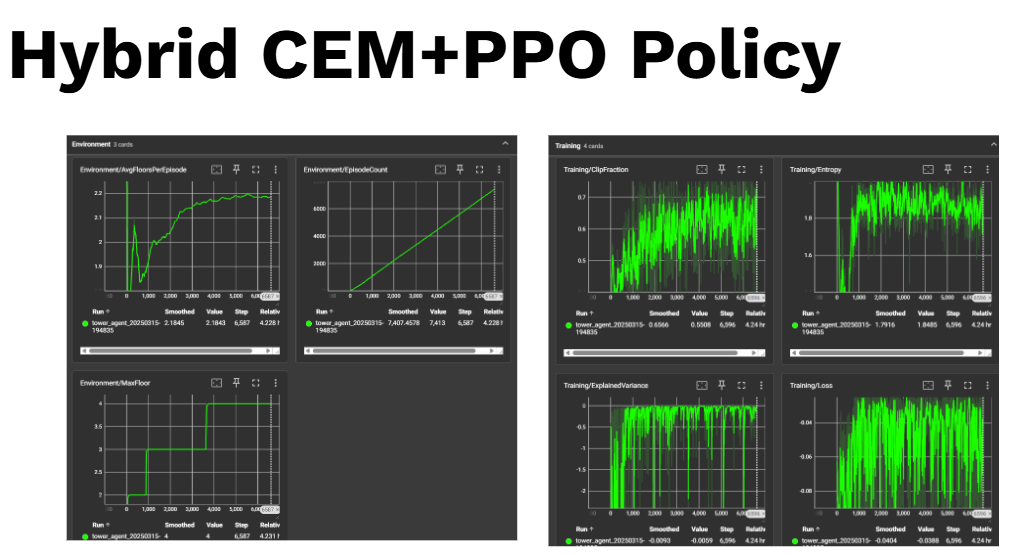 Figure 1: Episode rewards for CEM (Cross-Entropy Method) combined with PPO variant hitting floor 4 max.
Figure 1: Episode rewards for CEM (Cross-Entropy Method) combined with PPO variant hitting floor 4 max.
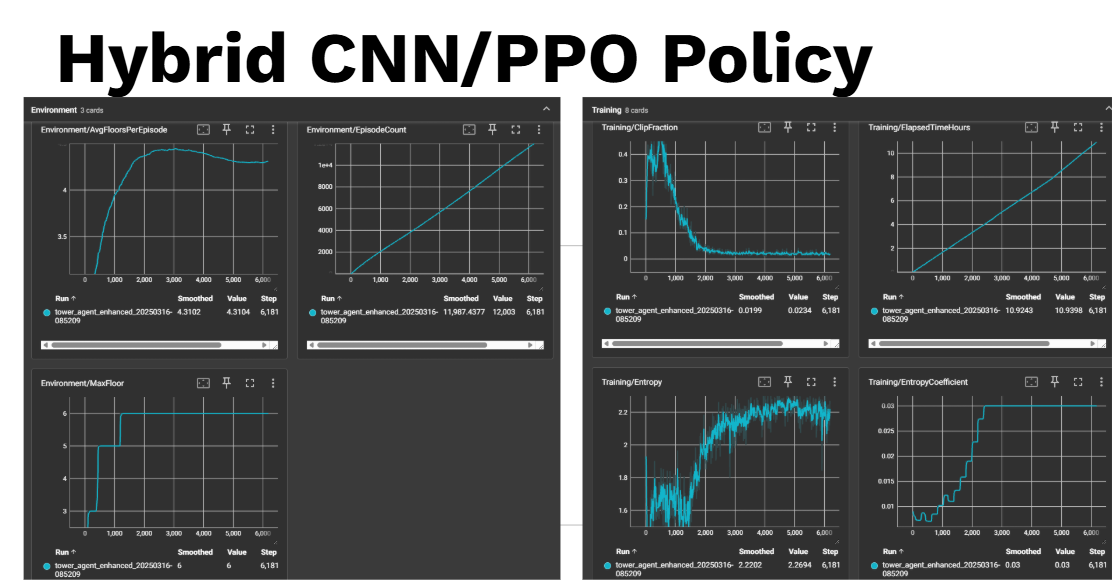 Figure 1: Episode rewards for PPO with a CNN (Convolutional Neural Network) variant, hitting a floor 6 max.
Figure 1: Episode rewards for PPO with a CNN (Convolutional Neural Network) variant, hitting a floor 6 max.
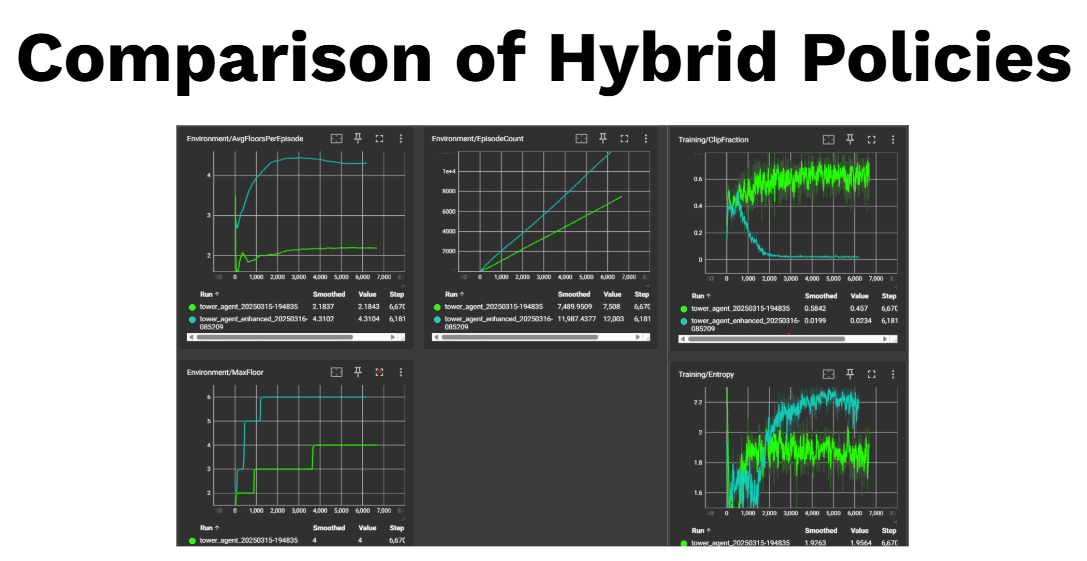 Figure 1: Comparison between the CEM+PPO and CNN PPO, our 2 hybrid approaches.
Figure 1: Comparison between the CEM+PPO and CNN PPO, our 2 hybrid approaches.
Qualitative Analysis
Through qualitative evaluation of agent gameplay, we identified several notable behavior patterns:
- Baseline PPO agents often got stuck in loops or failed to progress after finding initial rewards
- CNN-Based Architecture agents demonstrated the most sophisticated navigation and puzzle-solving abilities
- Hybrid CEM-PPO agents showed improved exploration behavior and better key-door navigation
- Demo-augmented agents showed more purposeful exploration and better key-door navigation
- LSTM+ICM agents exhibited improved memory-based behaviors, such as returning to previously seen keys
We analyzed exploration patterns across different algorithm variants:
- CNN-Based Architecture with dynamic entropy adjustment showed the most effective exploration-exploitation balance
- Hybrid CEM-PPO demonstrated strong systematic exploration behavior
- ICM-enhanced agents showed significantly more consistent exploration of unseen areas
- Demo agents efficiently navigated familiar room layouts but sometimes struggled with novel configurations
- Curriculum agents demonstrated better adaptation to increasing difficulty compared to fixed-difficulty training
Common failure patterns included:
- Repetitive actions when faced with obstacles
- Inefficient backtracking in maze-like environments
- Difficulty coordinating key-door interactions across long time horizons
- Struggle with precise platform jumping, particularly on higher floors
Discussion and Key Findings
The CNN-Based Architecture with batch normalization, dynamic entropy adjustment, and extensive reward shaping showed the best performance, reaching Floor 6. This suggests that a well-designed network architecture combined with appropriate learning dynamics is crucial for success in complex environments.
The Hybrid CEM-PPO approach demonstrated that combining different algorithms can leverage their respective strengths. Using CEM for exploration and PPO for policy optimization created a more effective learning process than either method alone.
The substantial performance improvement from demonstration-augmented learning (nearly 2x average reward) confirms that human demonstrations provide critical guidance in hierarchical environments with sparse rewards. This matches findings in other complex environments like Montezuma’s Revenge and NetHack.
The LSTM and ICM components showed complementary benefits:
- LSTM improved performance in scenarios requiring memory of previous observations
- ICM enhanced exploration in novel environments
- Combined LSTM+ICM approaches achieved robust performance across different floor layouts
From our extensive experimentation, we identified several key learnings:
- Exploration is critical - custom reward shaping with bonuses was necessary for success
- Hybrid approaches outperformed single algorithms in complex environments
- Dynamic parameter adjustment improved performance by balancing exploration and exploitation
- Appropriate neural network architecture makes a significant difference in learning stability and performance
- Good logging and visualization is essential for debugging and tracking progress
Despite our best approaches reaching high floors, several challenges limited further progression:
- Partial observability: Limited field of view made planning difficult
- Long time horizons: Actions and consequences separated by many timesteps
- Curriculum balancing: Finding optimal difficulty progression proved challenging
- Demonstration quality: Our demonstration dataset had limited coverage of higher floors
Our evaluation demonstrates that combining advanced techniques like demonstration learning, memory mechanisms, intrinsic motivation, dynamic parameter adjustment, and well-designed network architectures significantly improves performance in the Obstacle Tower Environment. The CNN-Based Architecture achieved the highest performance, reaching Floor 6, while other approaches showed strengths in different aspects of the challenge.
References
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347.
- Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv preprint arXiv:1801.01290.
- Pathak, D., Agrawal, P., Efros, A. A., & Darrell, T. (2017). Curiosity-driven Exploration by Self-supervised Prediction. In Proceedings of the 34th International Conference on Machine Learning.
- Juliani, A., Khalifa, A., Berges, V. P., Harper, J., Henry, H., Crespi, A., Togelius, J., & Lange, D. (2019). Obstacle Tower: A Procedurally Generated Challenge for Reinforcement Learning. arXiv preprint arXiv:1902.01378.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … & Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.
- Burda, Y., Edwards, H., Storkey, A., & Klimov, O. (2018). Exploration by Random Network Distillation. arXiv preprint arXiv:1810.12894.
AI Tool Usage
For this project, we used AI tools in the following ways:
-
Code Generation: We used GitHub Copilot to help with implementation details of the algorithms, particularly for boilerplate code and common reinforcement learning patterns.
-
Debugging: We used ChatGPT to help debug implementation issues with the LSTM integration and the Intrinsic Curiosity Module..
No AI tools were used for the core algorithm design, the evaluation of the results, or the interpretation of the findings, which were entirely our own work.